1. 背景
1.1 环境
首先列出系统环境以及相关组件的版本:
- 系统:阿里云2C4G轻量应用服务器-ubuntu20.04;
- docker:24.0.5;
- 服务:
- python:3.10;
- python package:
- sanic==22.6.1;
- websockets==10.0;
- SpeechRecognition==3.10.1;
- requests-toolbelt==1.0.0;
- requests==2.31.0;
- vosk==0.3.45;
1.2 业务背景
业务上预期实现一个“智能问答”的模块,其中包含一项功能:由用户输入语音,将其识别成文字后交给大模型进行处理,最后将用户的语音提问以及大模型输出的回答一并呈现在前端对话框。
该项目的后端服务基于python,而本人被分配到的任务则是基于vosk的中文语音识别模型以及SpeechRecognition包和sanic框架来实现“用户输入的语音到对应文字的识别”的web接口。对于该接口,其路径为/api/audio/convert,预期从请求的body体中读取wav格式的音频字节流,并返回识别后的中文文本。
在本地进行开发时,本人采用的前后端通信的架构如下:
- 前端所有的api请求会先发送到nginx网关上,对应本机端口8080;
- 在nginx网关中设置路由规则,然后将前端的请求转发到实际处理的后端服务对应的端口8091上;
- 后端服务采用docker容器进行部署,后端服务在容器内的进程端口映射到本机的8091端口上;
即简单的“前端-网关-后端”的这样一个单体应用的架构。
1.3 问题
在基于1.2的业务背景的基础上,遇到的问题可以整理为:
- 前端调用测试接口
/test时,得到预期结果; - 录入语音并调用
/api/audio/convert接口时,在接口等待一段时间后返回错误码404; - 跳过网关,直接请求接口
/test与/api/audio/convert,返回错误码502;
2. 排查过程
遇到这类问题,笔者本人最先考虑的是首先是前端发起的请求能否正常到达服务,其次是是否服务本身出现了问题,所以沿着这个思路,笔者先做了以下的排查工作:
首先查看网关是否能够正常接收前端发起的请求:
查看nginx的
access.log与error.log,发现nginx能够正常接收前端发起的请求;查看容器是否正常运行:
docker ps查看docker容器运行情况,发现容器正常运行;查看容器内服务是否正常运行:
docker logs查看docker容器中的服务日志,发现日志打印了一部分收到请求后预期打印的内容,同时日志并未打印任何程序异常;
检查到这里,可以首先确认容器正常运行,同时前端的请求的确到达了网关,并由网关正确地转发到了相应的后端服务上,后端服务接收到请求后执行了部分相应的处理逻辑,但并没有走完全程。这中间应该是发生了异常的退出,但却没有被业务逻辑以及web框架自身捕捉到这个发生的异常。再结合请求这个/api/audio/convert接口时产生了较长的等待,于是考虑是否存在机器资源耗尽从而导致请求失败的可能性。
于是到阿里云的控制面板里查看监控,发现在接口请求期间,机器出现:
- 内存发生了断崖式地下降;
- 磁盘高频读;
如图:
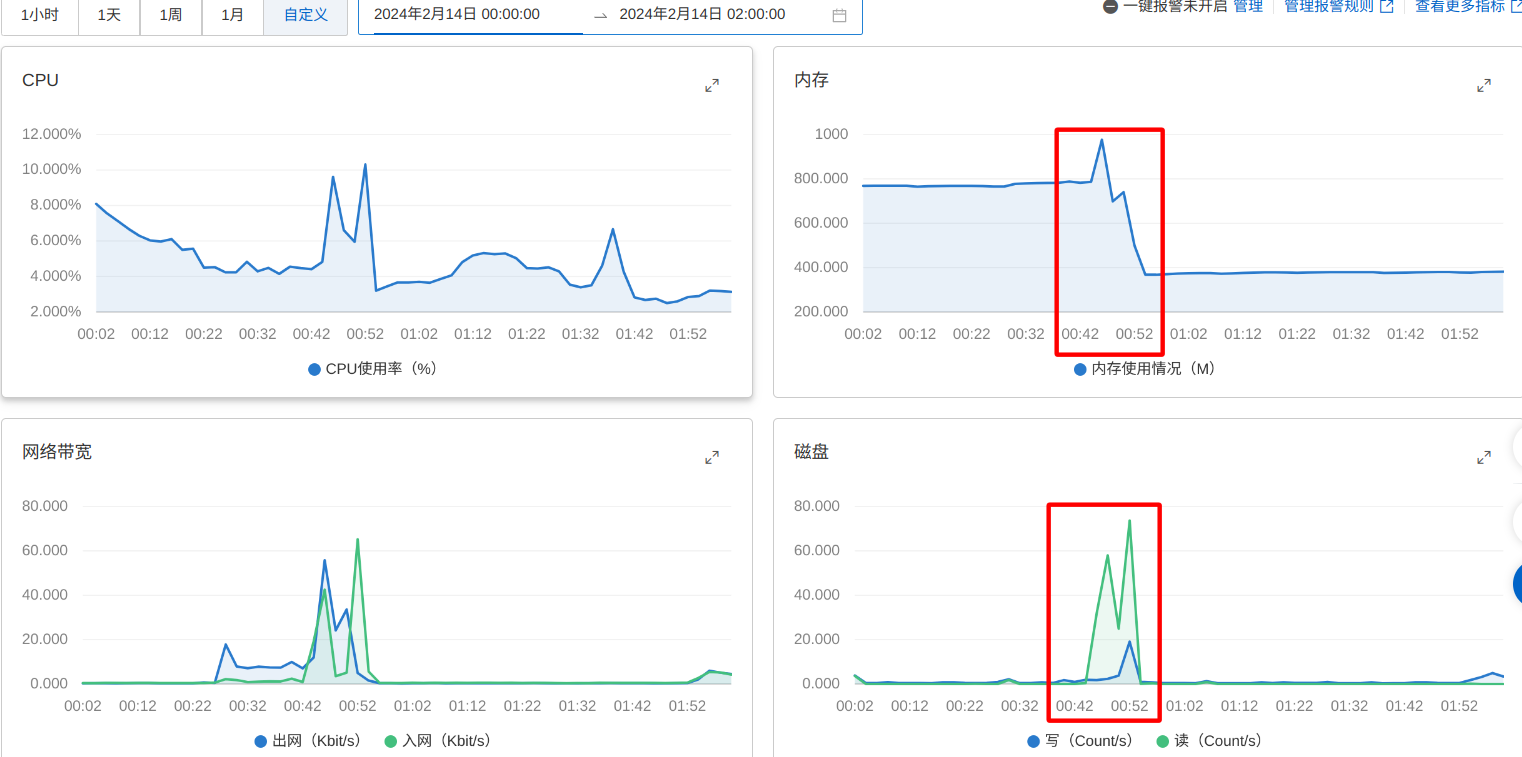
结合先前对容器服务产生“异常退出”的可能性的判断,高度考虑服务进程大量占用内存,系统内存耗尽导致对应的进程被内核OOM kill掉,所以整个服务挂掉,为接口调用失败的原因。
为了验证猜测,首先重启容器,并且重复先前的操作,使用top命令以及free -h命令观察对应进程的资源占用:
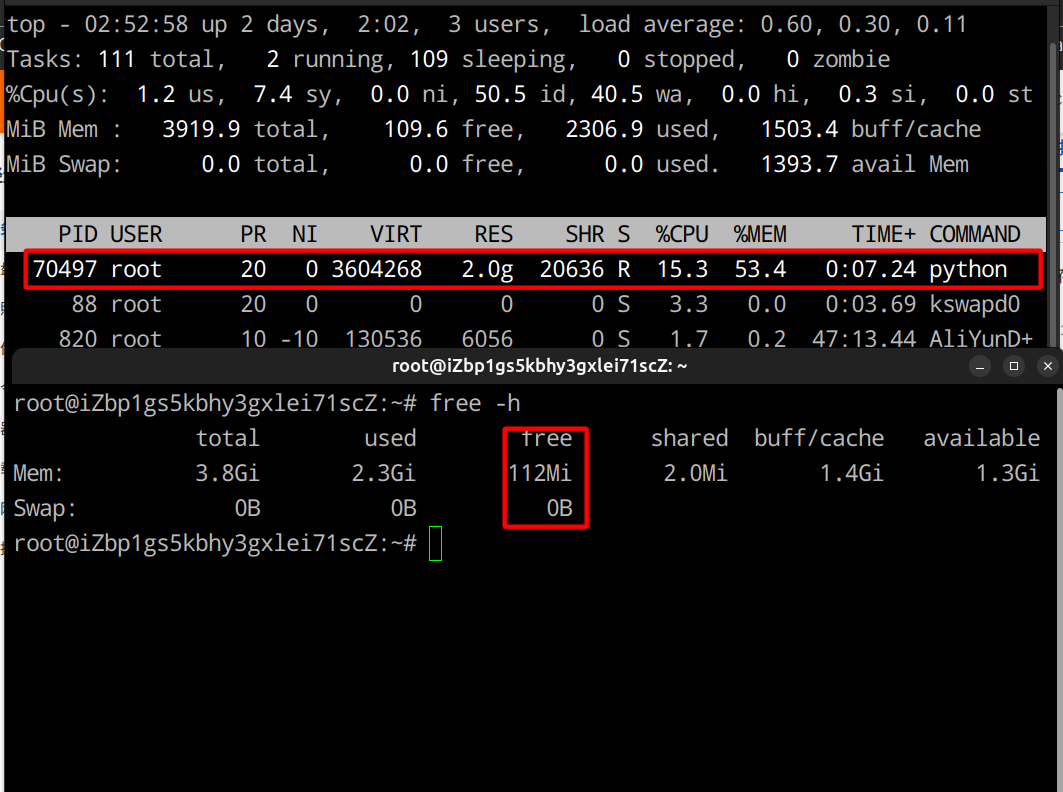
发现后端的服务进程确实产生了大量的内存占用,最后使用dmesg -T命令,查看是否真的产生了系统级的OOM,发现的确发生了OOM,如图:
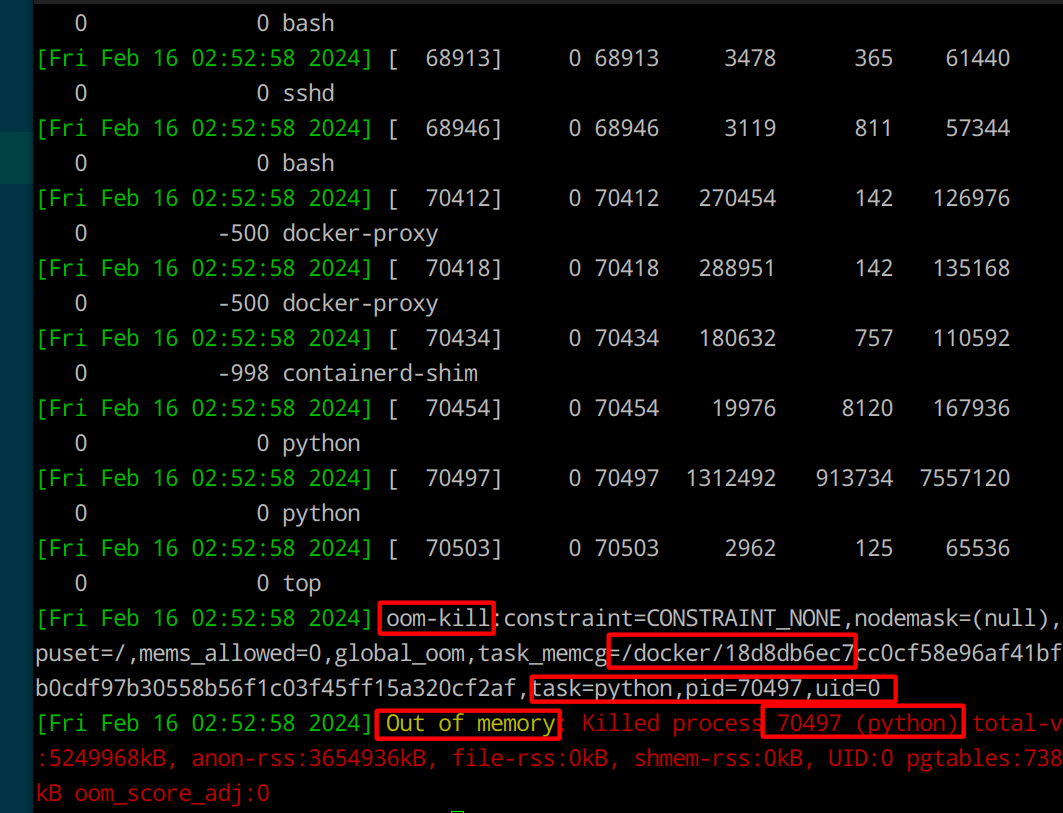 至此,我们可以说OOM是板上钉钉,证据确凿的事情了——也就是说
至此,我们可以说OOM是板上钉钉,证据确凿的事情了——也就是说
我们后端的服务在运行期间占用了大量的内存,导致系统oom,进程被干掉导致服务挂掉,从而导致接口报错。
这里面比较有意思的是,具体执行任务的进程是对应docker容器进程的孙辈进程,因而该进程被oom kill掉后不会影响容器进程的运行,所以查看容器运行状态时,可以看到容器运行正常。
最后,发现是python服务调用的模型自身文件有2.1个G的大小,机器本身仅有4g的内存,因此将其从磁盘上读入内存时,容易造成机器内存耗尽的问题。最后换了一个轻量级的,60多M的模型,之后接口就正常工作了。
3. 结论与收获
这是一个非常典型的因为资源耗尽导致系统oom kill掉服务进程,从而导致整个服务挂掉,接口调用失败的案例。排查这类问题首先要做好的就是各级各层的日志与监控需要具备(系统的可观测性),这样才可以逐步缩小问题范围;同时对排查的问题范围要有敏感度,接口调用失败有可能是接口本身不够健壮,运行过程中产生了异常,也有可能是系统层面的问题,如进程导致系统资源耗尽从而被内核kill掉——而前者一般是可以通过服务应用的日志观察到的,后者需要进一步借助系统层面的观测。
从具体的“术”的层面,大致学习到了:
top -p命令查看具体进程的系统资源占用;free命令查看系统内存的使用情况,本文中使用free -h命令;dmesg命令可以查看系统内核日志,本文中使用dmesg -T命令;
*4. 延伸与思考
笔者认为,从这篇文章出发,顺带着延伸开来,也可以试着学习和思考一下以下几个问题:
docker的虚拟化的机制是怎么样的?
为什么用
ps -ef命令查看的时候,显示的是:docker容器一个进程A,容器内image写Dockerfile时run的python src/main.py一个进程B,最后调用的python是宿主机上的/usr/local/bin/python,这个python对应的一个进程/usr/local/bin/python src/main.pyC,并且ABC的关系是:A为B父,B为C父;对于更加复杂的微服务架构以及分布式系统,这样的系统的可观测性有没有什么实践案例,是怎么设计和做的?
这里的解决方法是采用更轻量的模型,部分也是受制于笔者本人对本地开发环境的预算以及公司基建的不成熟,假如服务器资源更充足,要求在不降低模型质量的前提下,对应的解决方法又该如何设计和实现?