
1. 背景
上周五下午15:20分左右的时候,接到用户的反馈说系统进不去。在访问了网站的线上地址后,我发现UI正常渲染,但是所有的接口都报502错误,于是考虑后端服务出现了问题。访问了Grafana监控后,发现后端的服务正常存活,但是出现了Full GC次数变多以及老年代的GC时长飙高的情况:
客户反馈因为周五是系统上报的截止日期,所以存在短期内流量较大的情况。为了尽可能最快地恢复系统并保证服务的可用性,我选择了临时重启服务。在服务重启完毕后,接口恢复正常并持续工作了一段时间。但是在下午15:40左右,又接到了部分用户对系统不可用的反馈。在与客户协商并取得同意后,我选择临时关闭了生产环境机器上的一些次要服务来为当前服务腾出资源,同时去调高分配给当前服务的最大堆内存的大小以及新生代区的大小,启用了G1垃圾回收器,最后保障了此后服务的可用性。
由于造成服务假死的原因有很多,所以需要进一步地梳理和复盘才能确认出服务不可用的原因。下面的“复盘”环节将给出各个时间节点系统的一些指标的情况并结合相对应的表现去试图还原系统走向假死的这一个过程。
2. 复盘
通过抓取和分析当天的系统与服务的指标,以及相对应的系统外在的表现,按照时间顺序可以罗列出以下的几个重要时间点:
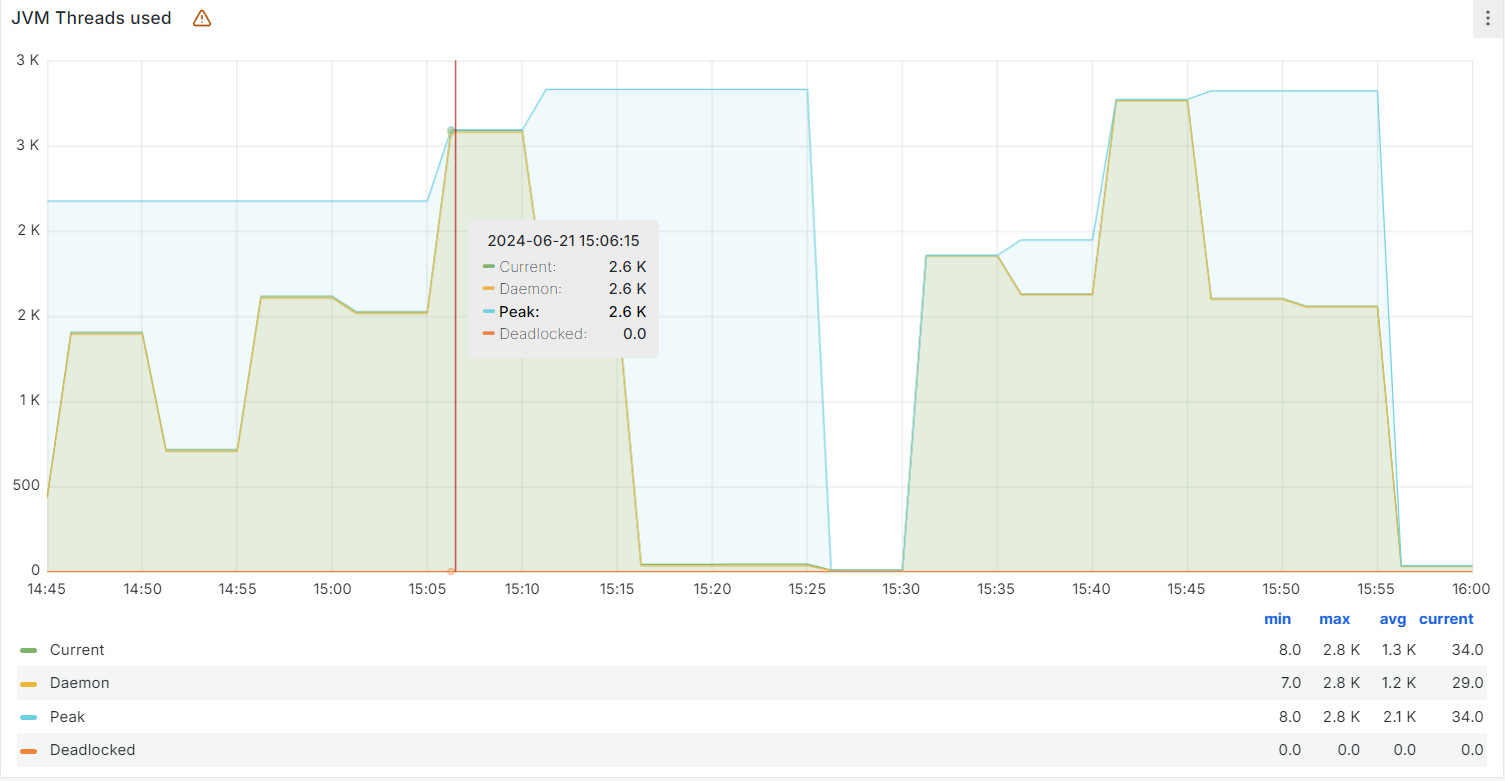
下午15:05分左右出现了JVM线程数的一个峰值,峰值时JVM线程数达到2.6K的一个量级;
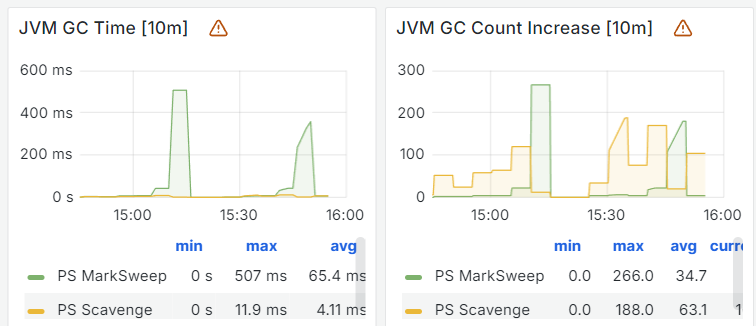
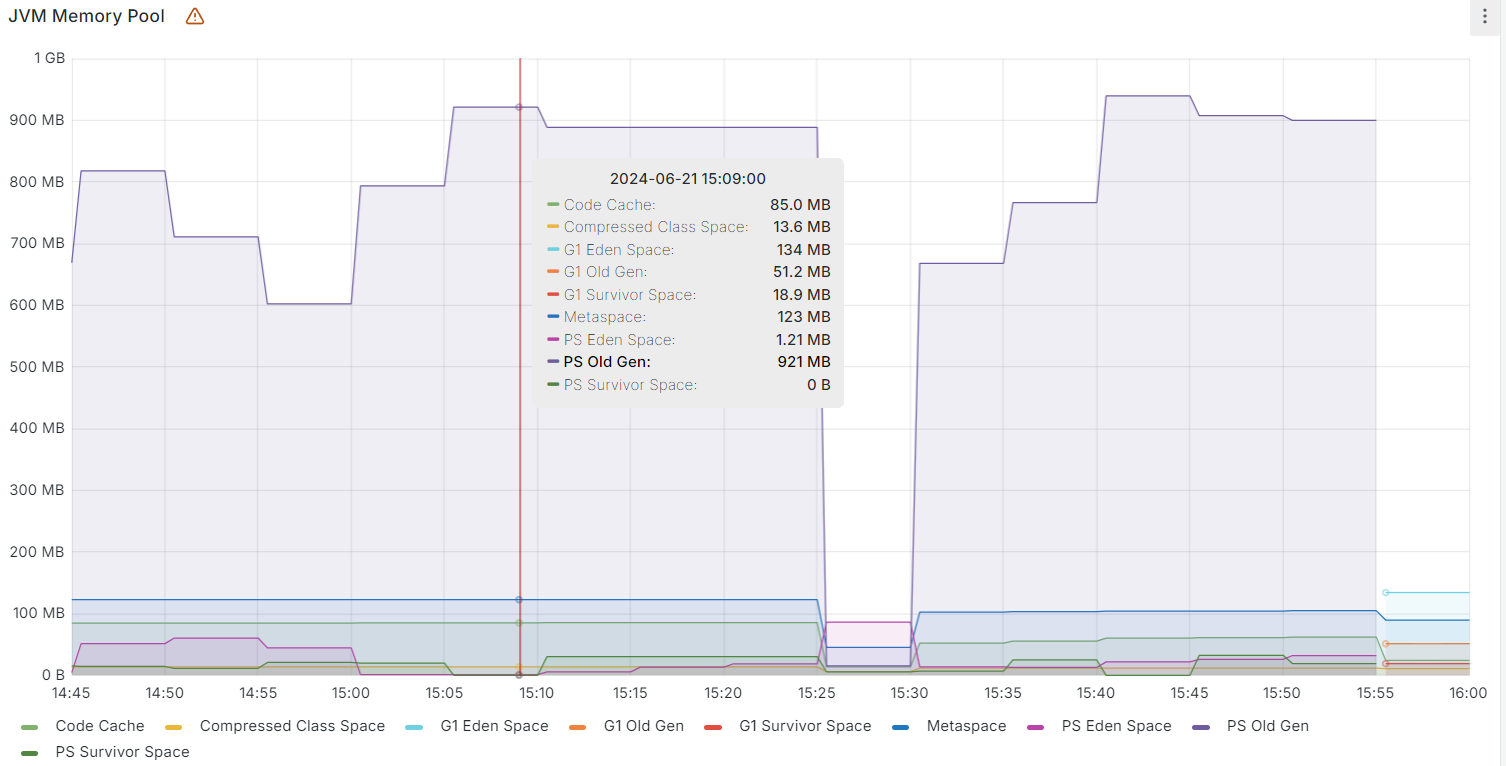
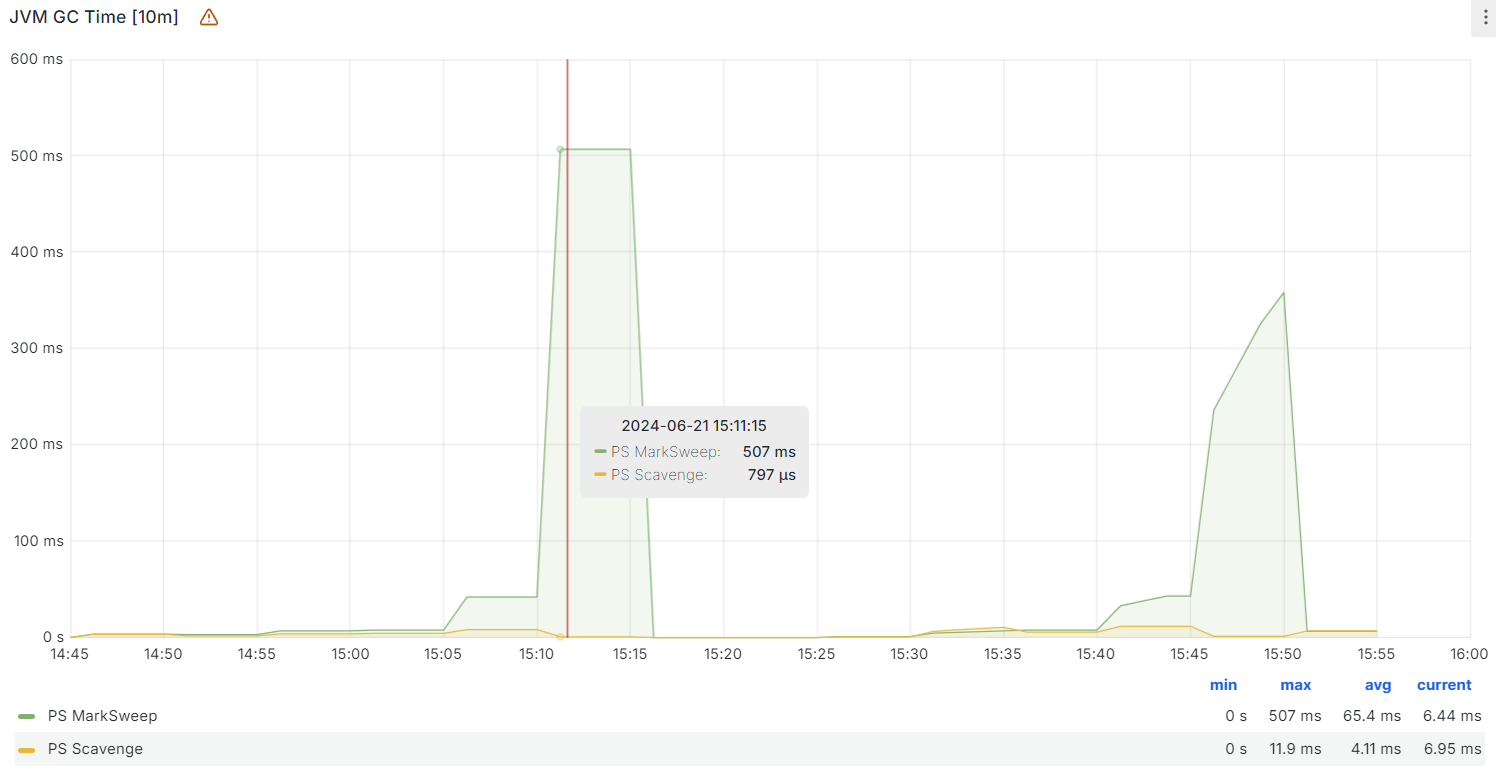
下午15:10分左右,老年代内存接近占满,然后开始频繁触发Full GC,同时Full GC的时长也开始增加,15:10分左右的一次标记清除算法耗时达到了507毫秒;
与此同时系统CPU使用率开始飙高,从平时峰值10%多变成了40%多(时间用的UTC+0所以差8个小时);
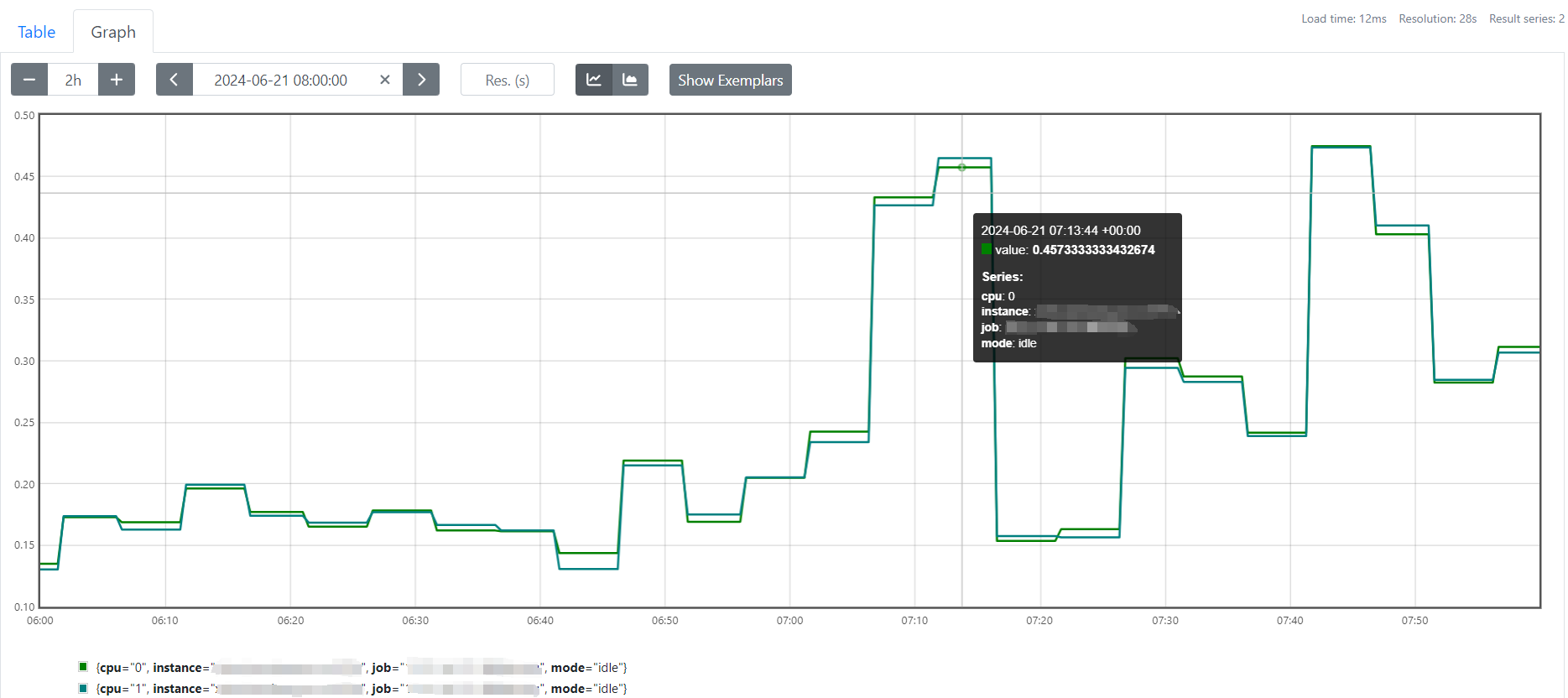
下午15:22分接到用户反馈,称系统无法正常使用,核实后发现系统接口均报502错误;
下午15:25分完成系统的第一次重启,重启后接口正常工作;
下午15:40分左右系统又出现了JVM线程数的新峰值,量级在2.8k,同时接到部分用户反馈系统不可用的情况;
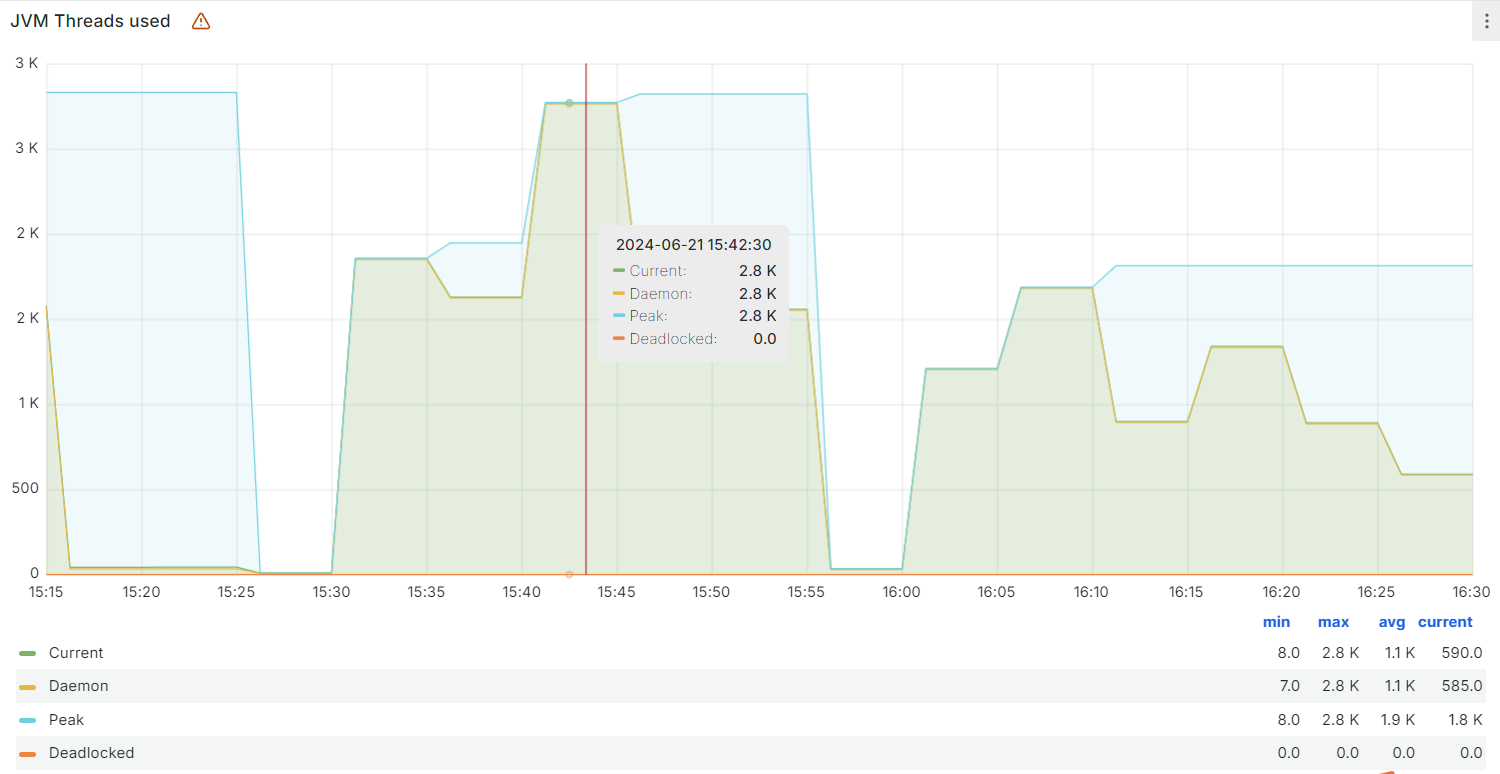
下午16:03分,关闭了生产机节点上的次要服务,同时调整服务的启动参数,完成了系统的第二次重启,此次重启后系统没有再发生不可用的情况;
最后解决问题的思路整体上遵循“临时扩容”的办法,将分配给Java服务的资源调大后问题就没有再出现了——而原先该服务的Java进程的启动参数中,分配给该服务的最大堆内存为1024M。这说明我们系统不可用的原因定位到的位置是应用层,发生的问题可以归纳为资源耗尽。同时,在事后排查接口访问与耗时这一块相关的数据时,我们发现出现服务不可用的时候系统的QPS并不高(只有个位数),同时系统的用户服务的接口中,有三个接口的耗时均达到了5s以上:
sysUser/listByUser:平均耗时11.2ssysUser/list:平均耗时6.82ssysUser/listByOrganization:平均耗时5.67s
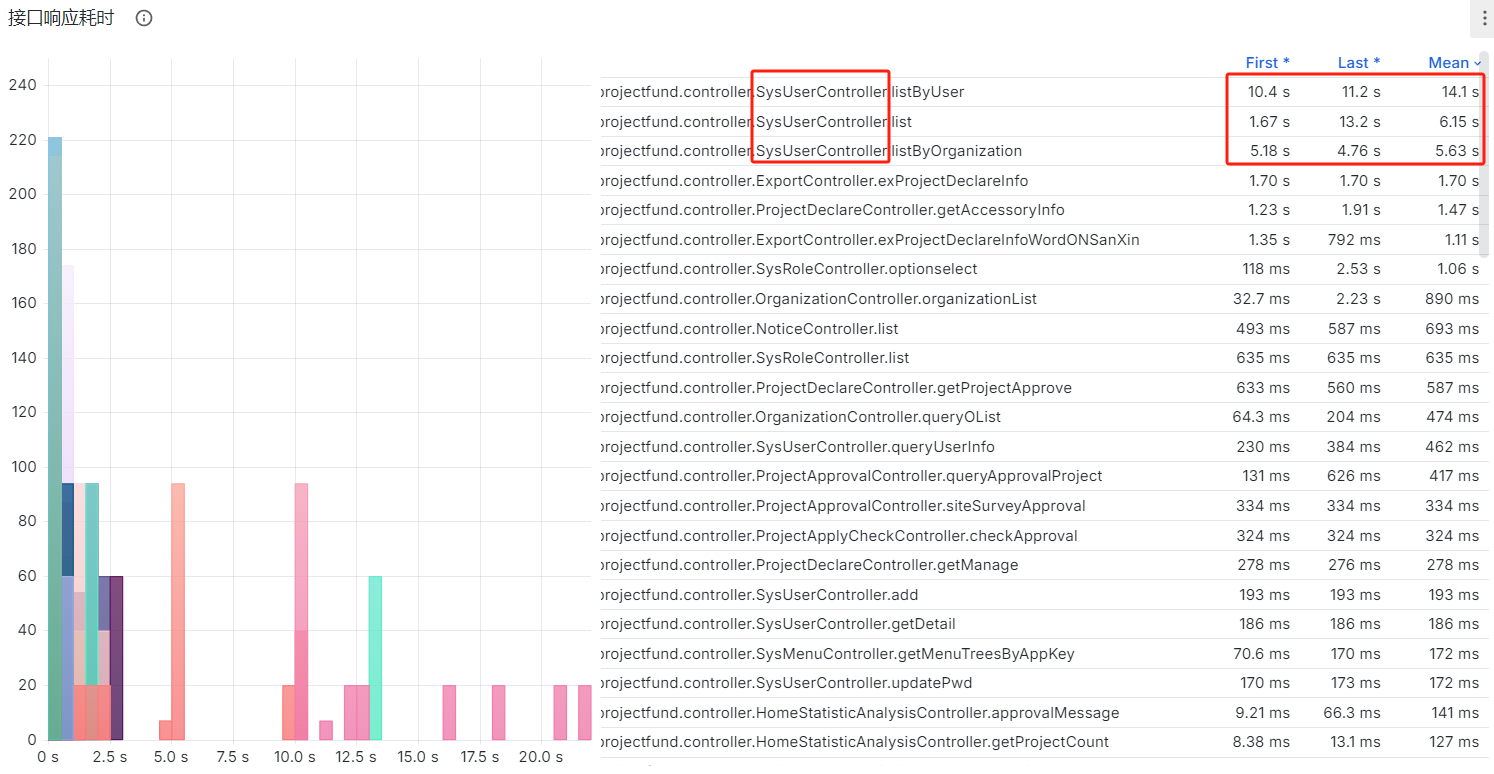
因此,当时系统的情况可以概括为:系统的JVM线程数飙高,堆内存耗尽,频繁Full GC的同时QPS并不高。推测原因是这些慢调用在系统流量较大时,将大量的线程阻塞住,导致一方面老的请求尚在处理,新的请求过来后,SpringBoot内置的Tomcat容器不得不启动新的线程去处理请求,新的请求进来的速度远高于已有请求的处理速度,最后资源耗尽,最终服务不可用。
3. 几个接口为什么慢
既然我们定位到了接口的慢调用导致了流量较大时系统大量线程被阻塞,就需要去查看相关的代码,做了哪些操作可能引起如此高的耗时。
以listByUser为例,我们排查这个接口的实现逻辑后,最终定位到这样一处for循环:
1 | for (UserOrganizationRelation userOrganizationRelation : sysUserList) { |
这里的sysUserList是根据事先传入的角色参数查到的对应角色下的所有用户的user_id组成的一个entity列表。在for循环内部,代码其实就是做了两件事:
- 获取
String类型的userInfo变量; - 解析
String类型的userInfo变量,并将解析出来的属性赋给sysUserList中的实体;
这里的userInfo的获取调用了一个叫SzsnApiUtil的静态方法,结合类名以及拿到userInfo并转换成JSONObject(实际上就是在做反序列化)的行为且根据code属性是否等于200来做后续的逻辑来看,大概率获取userInfo的过程就是一次远程调用的过程。只不过这个远程调用我们实现稍微封装了一下。如果可以验证SzsnApiUtil.getUserInfo方法内部就是一个远程调用用户服务的接口,那么我们等于是在for循环内去执行远程调用,那么接口耗时如此之高,能达到10s以上,也就解释得通了。最后,在查看SzsnApiUtil.getUserInfo的内部实现逻辑后,我们发现该方法就是一次裸的远程调用。
同样的道理,在查看了另外两个耗时较高的接口的内部实现逻辑后,也发现了for循环内执行远程调用的情况,这也就能解释得通为何这三个接口的平均耗时如此之高。
4. 优化接口性能
我们知道,计算机在访问存储的时候是按照“由近及远”的方式的,越是近的,读取的速度就越快。从CPU内的寄存器里读取一次数据,在现代CPU上可以在不到1纳秒之内完成(1个时钟周期),而从CPU的L3 Cache读取一次数据,再到RAM中读取一次数据,在现代硬件上耗时也都是纳秒级的;但是如果需要从硬盘上读取数据,哪怕是SSD,耗时都起码在微秒级;如果涉及到网络I/O,那么耗时从毫秒到秒就不等了。可想而知,在for循环里发起网络调用,将会给系统带来多大的负担。一旦遇到突发的流量,并发数稍稍高于平时,这些慢调用就可以把本来可以用于处理外部请求的线程阻塞在I/O上,进而导致可用线程大大减少,JVM不得不创建更多的线程来处理请求。而线程的创建,对象的创建都是有开销的,只限定1个G的堆内存,外面还有流量进来,里面的线程还在被慢调用独占,一来一去,服务最终资源耗尽,出现了假死。
仔细分析这个场景,其实我们不难想出一种合理且简便的优化方法——用户数据是一个典型的“读多写少”的数据,我们访问系统的服务时,经常需要查询用户数据,但是往往我们修改用户数据的次数远小于读取的次数,一个用户可能每天都会访问系统,但很少说用户每天都要修改用户信息。因此,针对这一种读多写少、且本身为热点数据需要被系统大量其它服务访问、且I/O方式都是通过网络调用来实现的数据,我们完全可以引入缓存去做数据读写的优化。
例如,我们在读取用户信息时,首先从缓存中查找数据,如果缓存命中,我们直接返回缓存中的数据;如果缓存未命中,我们发起一起网络调用来获取用户信息,同时将获取到的信息写入缓存,方便下次查询时直接返回。在后端服务中,缓存常用的选型有远程缓存Redis/Memcached,以及本地缓存例如Guava缓存甚至Java内置的Map。这里选用Redis来作为缓存,毕竟Redis操作简单、效率好且提供了很多开箱即用的功能,不占用Java服务的内存,如果将来服务做多实例也无需进行大量相关的改造。
改造后的代码如下:
1 | if (redisUtil == null) { |
这里将缓存时间设置成了15分钟,主要是考虑了在突发流量的情况下,15分钟的窗口就能避免相当多的请求去走远程调用;如果流量不密集,两次请求时间超过15分钟,那么即便缓存过期了,系统内还是有充足的线程余量来处理请求。但这样做也带来了数据不一致的风险,假设用户在15分钟的窗口内修改了用户数据,那么用户服务是不会同步写Redis的,此时用户再访问系统拿到的就是旧的数据。针对这种情况,我留了一个后门接口来删除Redis内所有保存的用户信息的缓存来做兜底。
接口优化后,依赖于这个SzsnApiUtil.getUserInfo的三个接口耗时基本有两倍以上的提升(相同的时间下同一接口调用次数至少是之前的2倍),以上周六到当前为止作为时间窗口来检查接口调用耗时:
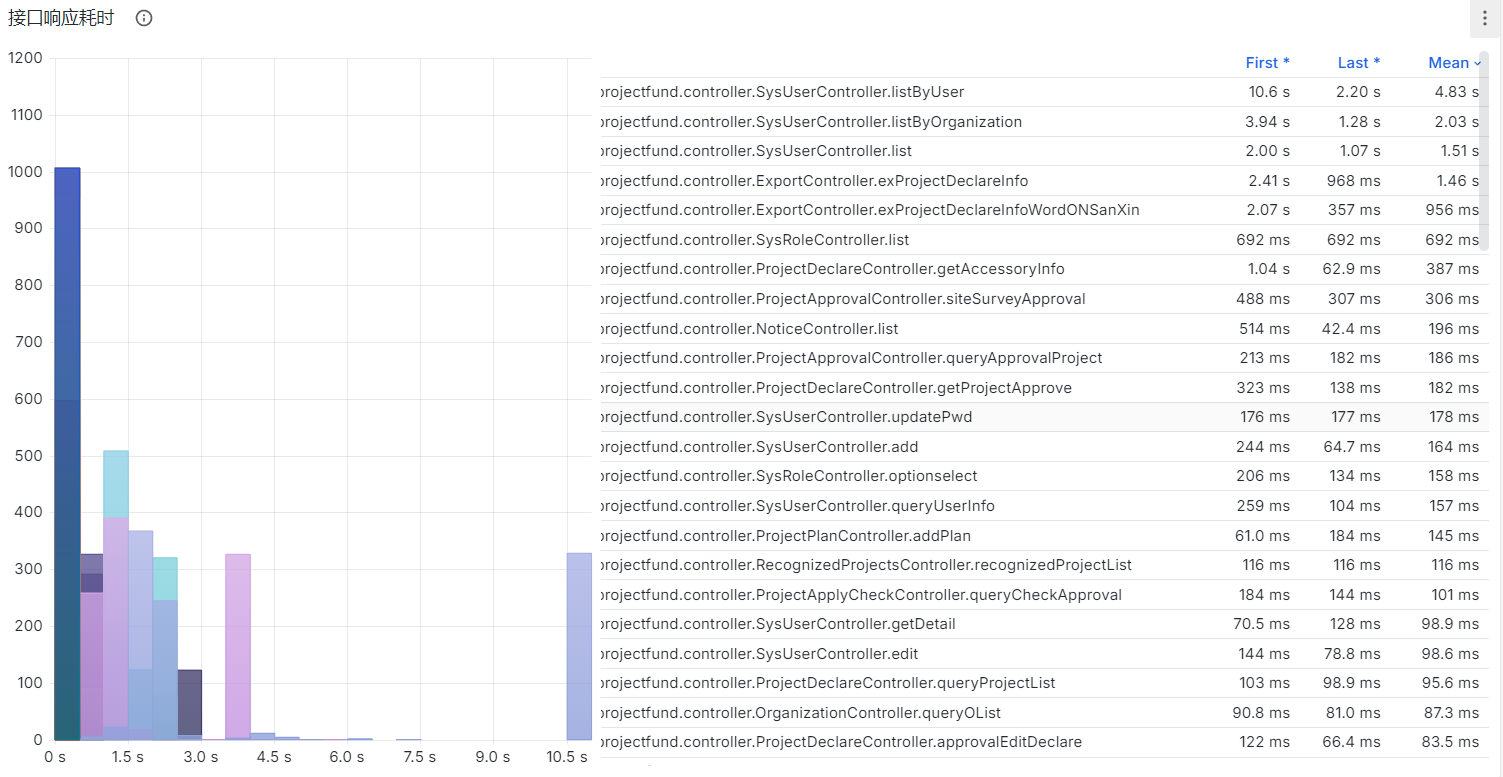
优化完成后,这周一下午四点到五点之间也有一波短暂的流量峰值,这一次系统完全能够正常工作。
除了接口优化以外,考虑到内存管理上尽量避免产生过多的碎片影响大对象的分配和保存,项目的服务是基于JDK 8的,因此后续还将JVM的GC收集器从CMS收集器换成了G1收集器。